
AI原生 · 全栈自治:企业级原生智能运维平台的架构革命
去年,一位在军工集团担任技术专家的师兄跟我倒了番苦水:“我们运维部监控着近万个指标,可故障真发生时,还是得联合多个部门几十名资深工程师,在海量日志里人工排查 2 小时” 结合现状细想,如今企业 IT 架构正朝着 “云 - 边 - 端 - 智” 全域融合的方向发展,数字孪生与工业互联网也深度交织,传统运维 “被动响应、依赖人工、数据割裂、价值模糊” 的固有痛点,已成为数字化发展的瓶颈。
基于自身工作经历和对技术的持续钻研,我翻遍了多年积累的 “技术笔记”:从 Google Borg 到 Meta Twine,从 K8s 到 openGemini,Datadog、IBM Instana,从工业 OPC-UA 到数字孪生 DES,把国内外主流的技术方案逐一拆解分析,最终沉淀出一套面向未来的智能运维方案。
这套方案立足当下,面向未来~以 “AI 为脑、数字孪生为体、业务为魂、生态为翼” 为核心理念,深度整合 n8n、DeepSeek、RAGFlow开源运维项目和现有工具链,构建覆盖 IT 设备、OT 终端、虚拟化、云资源、业务系统、工业设备的全栈智能运维体系,实现从 “故障修复” 到 “风险预判”、“人工操作” 到 “闭环自治”、“成本中心” 到 “价值引擎” 的三重跨越,最终目标是打造 “自感知、自认知、自决策、自执行、自进化、自协同” 的运维新生态。
核心愿景:让运维平台成为具备感知、认知、决策、行动与进化能力的 “数字生命体”。一个理解业务语义的运维专家(LLM+RAGFlow 行业知识库+智能体)、一个能调用一切API的自动化特工(MCP协议 + n8n编排 + Dify)、一个持续进化的学习系统(Ai大模型 + 强化学习 + 人类反馈)。
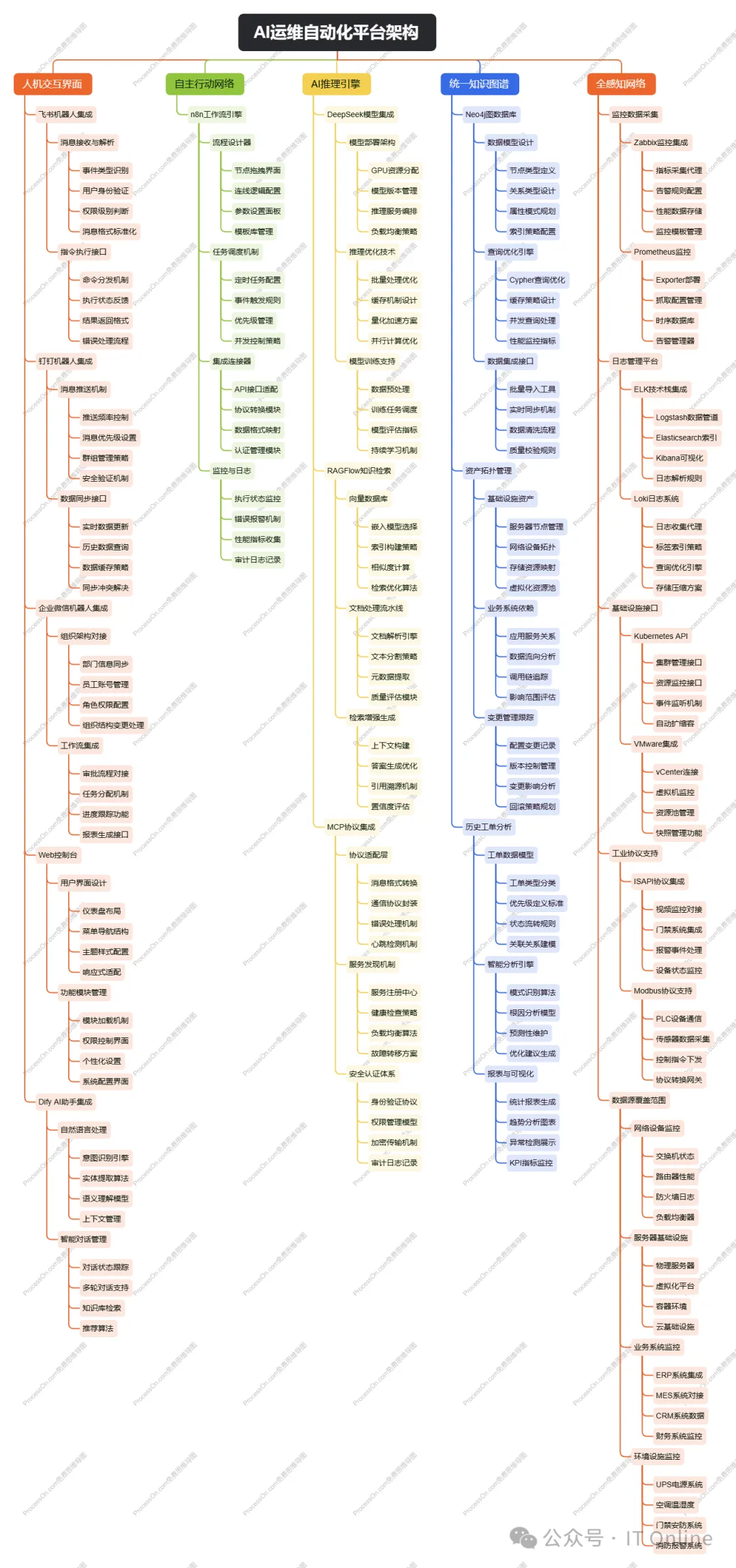
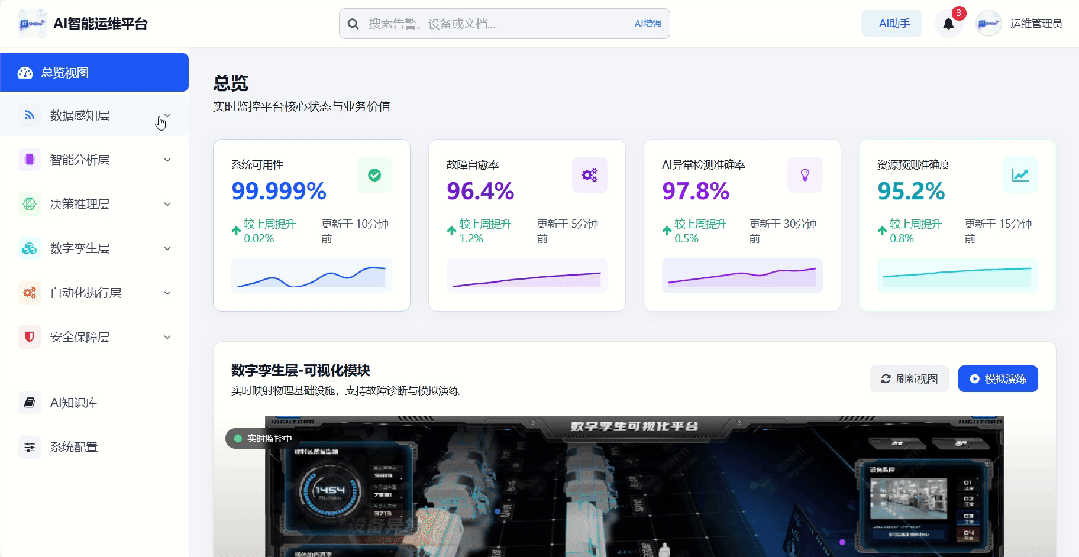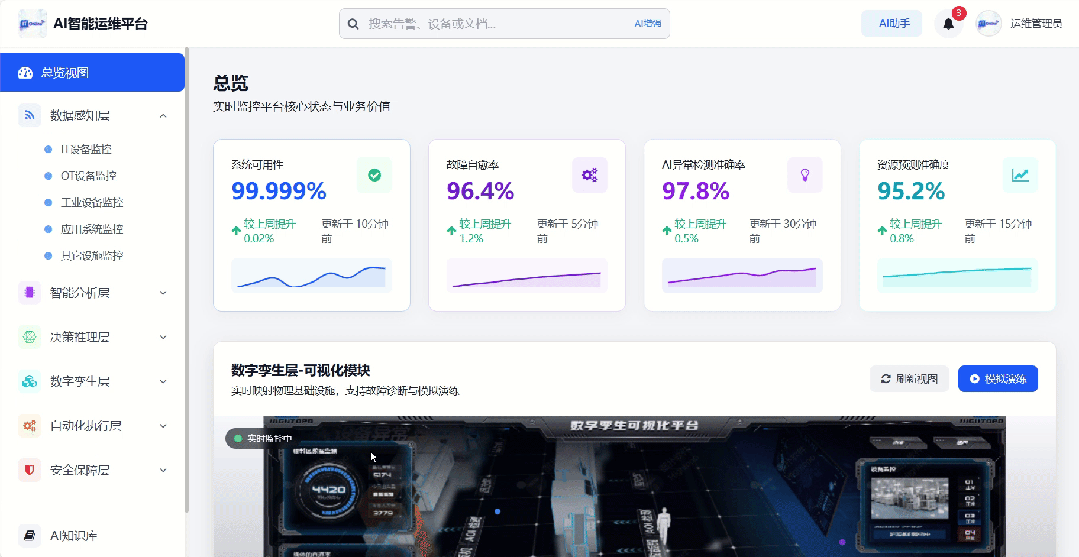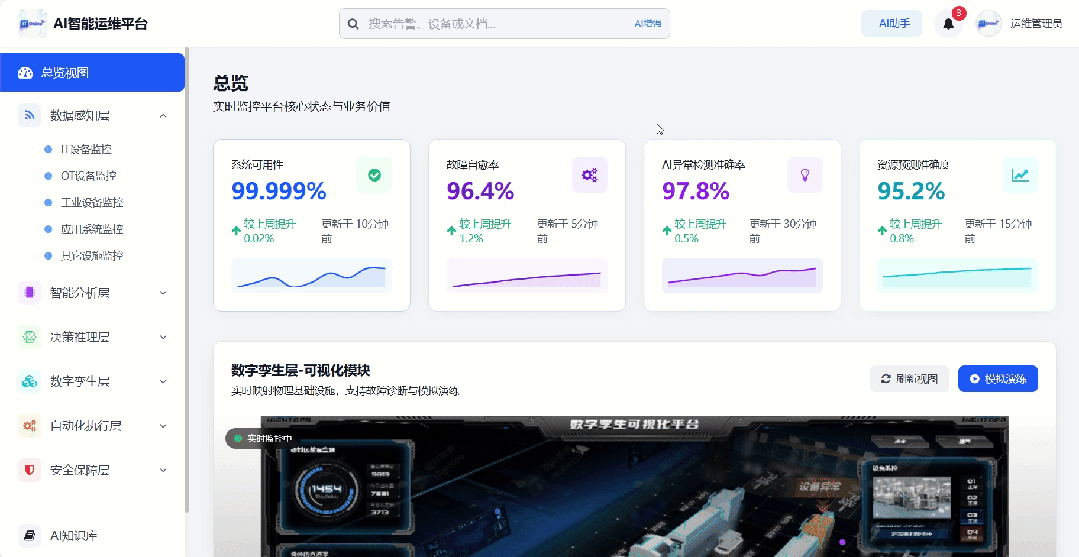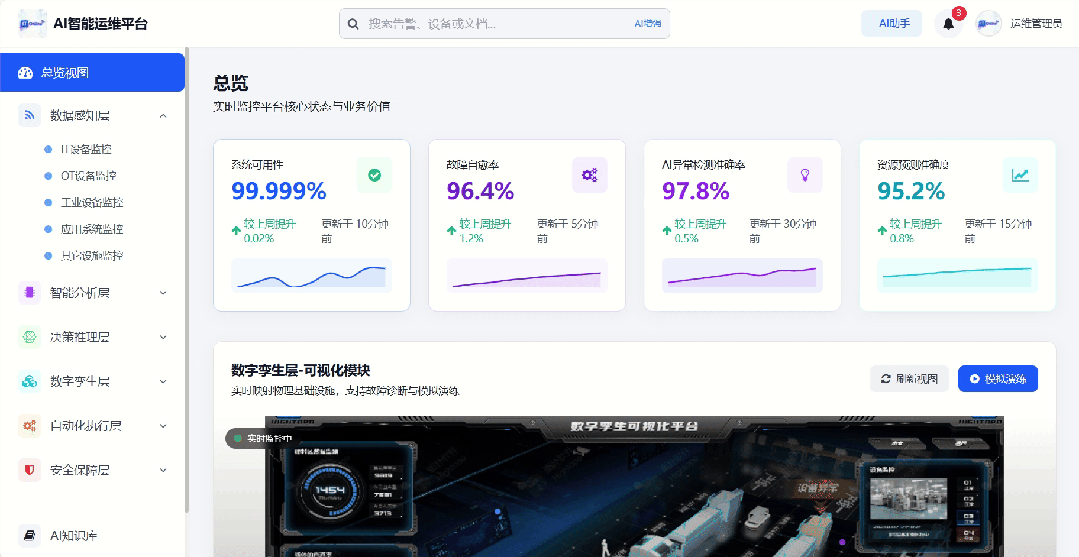
一、技术架构:六维一体的运维体系
采用“感知层-孪生层-数据层-智能层-编排层-应用层”六维架构,搭配“安全体系-标准体系-运营体系”三纵支撑,构建具稳定性、扩展性与前瞻性的技术底座,适配从中小制造企业到大型集团的全场景需求。
二、全息感知层 — 让设备「开口说话」
作为平台的“神经末梢”,通过多协议适配实现IT/OT设备/业务系统/工业设备的数据全方位接入,核心采集维度包括状态数据、性能数据、日志数据、业务数据四大类。
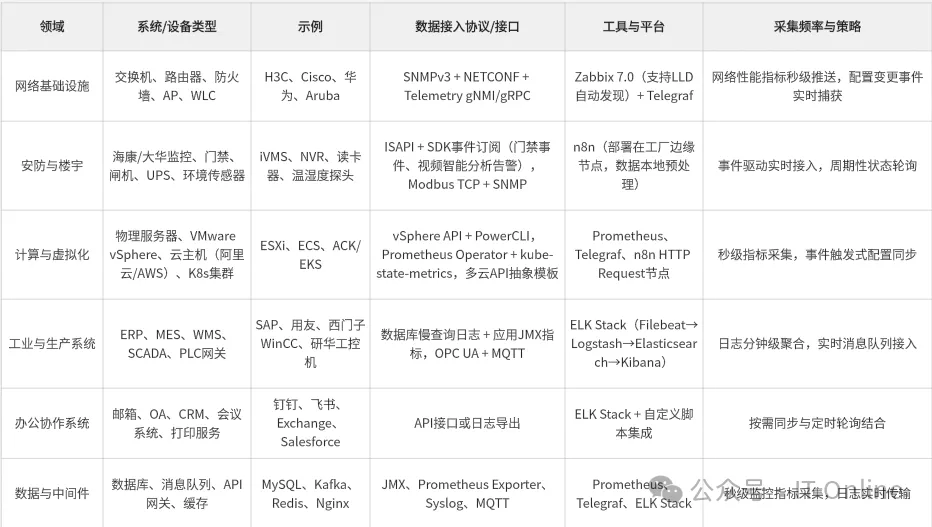
协议自适应:利用AI自动识别设备类型(如 H3C 交换机 、Palo Alto防火墙)动态加载采集模板,支持工业 /IT 协议(Modbus、Profibus、ISAPI、Kubernetes API 等)基本无需人工配置。
边缘预处理:在工厂边缘节点部署 n8n + 轻量 Flink,对视频流、传感器数据进行本地过滤(如仅上传 “视觉场景设备温度超阈值” 的异常视频帧)、特征提取(如 PLC 数据异常模式识别),带宽占用降低 95%,采集延迟控制在 100ms 内;
数据血缘追踪:每条指标自动打上 “设备 ID - 业务影响度 - 采集时间戳 - 采集节点” 标签,如 “交换机 Eth-Trunk1 错误帧→影响 3 号产线扫码入库→2025-11-21 14:32:15→边缘节点 Edge-03”,支持全链路溯源;
采集容错机制:某采集节点故障时,自动切换备用采集代理(如 Zabbix Proxy 冗余部署)确保采集连续性。
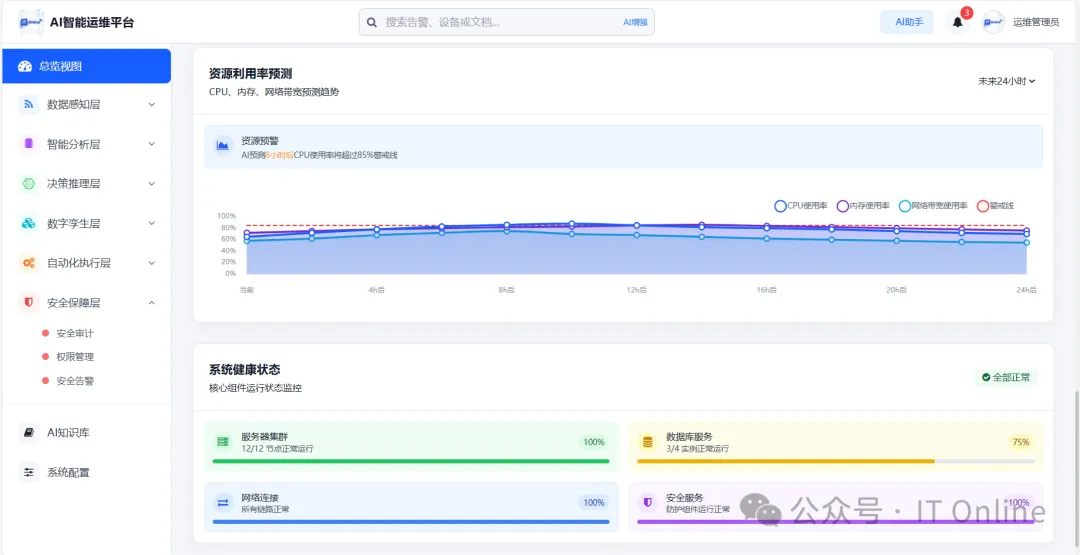
核心配置示例:
# AI驱动的预测性发现配置(支持零样本学习)
{
"ai_discovery": {
"model": "deepseek-coder-33b",
"prompt_template": "根据网络流量特征{{ $netflow_data }},预测潜在设备类型和监控指标",
"actions": {
"auto_discovery": true,
"proactive_item_creation": true,
"threshold_baseline": "llm_percentile_95" # AI动态基线
},
"self_healing": true # 自动修正误报
}
}
# AI驱动的动态LLD(低级别发现)
class AIDiscoveryModule(zbx_module):
def ai_predictive_discovery(self, network_scan):
# DeepSeek-Coder分析历史接入模式
prompt = f"历史设备接入日志:\n{self.get_logs(30d)}"
predicted_devices = deepseek.generate(
prompt,
schema={"device_type", "ip_pattern", "prob"}
)
# 自动创建监控项(置信度>0.9)
return self.auto_create_items(predicted_devices)VMware深度可观测性:
# Ansible Collection: vmware.vmware_rest + AI增强
- name: "AI驱动的预测性vMotion"
vmware.vmware_rest.vcenter_vm_relocate:
vm: '{{ vm_name }}'
placement:
cluster: "{{ ai_predicted_optimal_cluster }}" # AI推荐
datastore: "{{ ai_predicted_datastore }}"
reason: "{{ ai_migration_analysis }}" # 附带AI分析报告
when: ai_hardware_failure_probability > 0.7ELK-LLM认知管道:
# Logstash pipeline示例
input { beats { port => 5044 } }
filter {
ai_enrich {
model => "deepseek-llm-7b"
action => "log_semantic_tag" # 自动打业务标签
rag_query => "相似历史故障模式"
}
ai_aggregate {
window => "5m"
cluster => "异常模式聚类(未知日志识别)"
}
}
output {
elasticsearch {
index => "logs-ai-enriched-%{+YYYY.MM.dd}"
ilm_policy => "ai_smart_retention" # AI自动冷热分层
}
}三、孪生层:数字孪生驱动的运维空间
基于 Unity 3D+Neo4j 图数据库 + 数字孪生引擎,构建 1:1 还原的物理环境数字镜像,解决 “故障影响范围不可见、决策缺乏可视化支撑” 的痛点。通过 Kafka 实时同步感知层数据,确保数字孪生与物理世界的 “毫秒级对齐”;同时接入 RAGFlow 知识库的历史故障案例,如交换机故障场景自动推荐 “2024 年类似交换机故障的处理方案”。
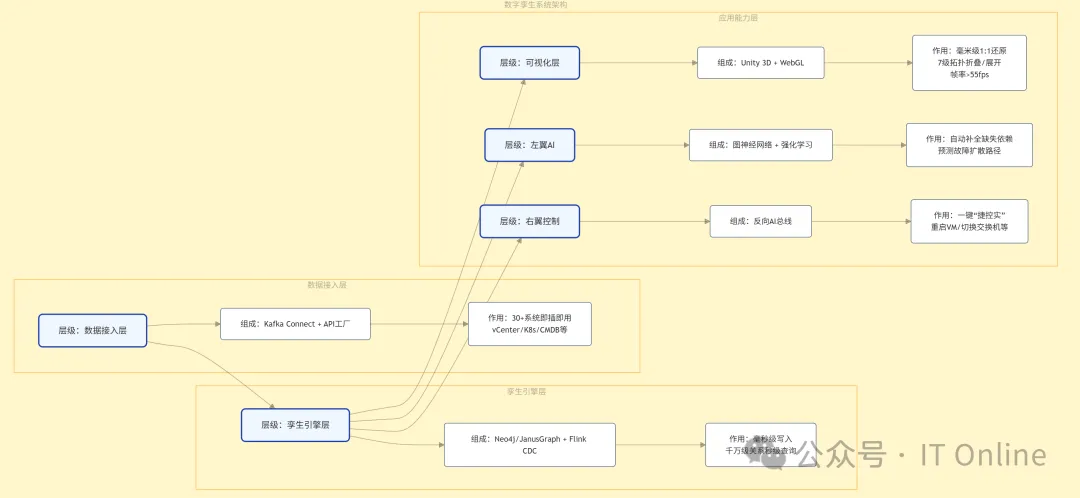
使用 Neo4j / JanusGraph 构建动态资产图谱:
[财务ERP] ←运行于← [VM-FIN-01] ←位于← [ESXi-05] ←机房← [上海IDC]
[上海IDC] ←受监控← [海康CAM-203] ←关联← [门禁-南门]
[VM-FIN-01] ←依赖← [Oracle DB] ←备份于← [NetApp存储]
3.1 孪生建模全流程
物理资产智能建模:通过 API 对接 CMDB、Kubernetes、VMware vCenter、工业 PLC,自动同步设备型号、位置、配置参数,结合 AI 图像识别(如摄像头拍摄设备位置,自动生成物理布局),减少 90% 人工建模工作量;
关系拓扑自动生成:基于资产依赖数据 + AI 推理(如 “Pod 调用数据库→数据库依赖存储→存储依赖网络”),通过 Neo4j 自动绘制全链路拓扑,支持行业专属拓扑分层手动调整优化(制造行业:物理层→网络层→OT 层→IT 层→业务层);
数据映射动态绑定:通过 Kafka Connect+Flink CDC 实时同步感知层数据,建立 “物理设备指标→孪生节点属性→业务指标” 的动态映射,确保虚实数据毫秒级对齐;
场景模板配置:制造(产线故障模拟)、金融(核心系统容灾演练)、零售(峰值流量推演)等行业专属场景模板,支持自定义规则(如 “模拟制造行业 PLC 停机,自动关联影响的生产工单”)。
3.2 核心能力
全链路拓扑可视化:自动绘制 “上海 IDC 机房→ESXi 主机→VM-FIN-01 虚拟机→财务 ERP→Oracle 数据库→NetApp 存储” 的依赖关系,点击任意节点可查看实时运行数据(如 VM-FIN-01 的 CPU 使用率、ERP 的订单处理量);支持拓扑分层展示(物理层 / 网络层 / 应用层 / 业务层),避免视觉混乱;
故障扩散动态模拟:当交换机 Eth-Trunk2 出现 CRC 错误时,数字孪生自动标红关联设备(如连接的 PLC、MES 服务器),并基于历史数据计算 “故障导致产线停工的预估时间”,支持故障扩散路径动画演示;
what-if 场景推演:例如模拟 “云主机扩容至 8 台” 后 CPU 负载变化、“核心交换机切换备用线路” 的业务中断时长,支持参数自定义(如 “扩容台数”“切换延迟”)推演结果导出为 PDF 报告,且可以对行业针对性模拟。
性能优化:采用 “轻量化建模 + 分级渲染” 技术,针对超大规模集群(如 1000 + 设备),仅渲染当前关注区域的孪生节点,降低前端渲染压力,确保操作流畅度(延迟 < 500ms)。

3.3 虚实联动机制
虚控实:通过数字孪生界面发起操作(如 “重启 VM-FIN-01 虚拟机”),自动转化为 API 调用(vSphere API),执行结果实时反馈至孪生节点;
实控虚:物理设备状态变更(如 “交换机端口关闭”),通过感知层实时同步至孪生节点,自动更新节点颜色(红 = 故障 / 绿 = 正常 / 黄 = 预警)。
四、数据层:湖仓一体的智能数据中枢
构建“实时流+批处理+向量存储”的湖仓一体架构,基于ELK Stack、Kafka、ClickHouse与Milvus向量数据库,实现数据的“存-管-用”全生命周期管理,为 AI 分析提供高质量、可追溯、可解释的数据底座。
4.1 核心组成:
实时数据湖:通过Kafka+Flink构建实时数据通道,接收设备与系统的实时指标,毫秒级响应,实现 exactly-once 语义,保障数据一致性,支撑故障告警与即时决策;
离线数据仓:采用ClickHouse存储历史性能数据(保留周期1-3年),MySQL存储配置与工单数据,HDFS存储非结构化日志与文档,历史沉淀,赋能长期分析。
数据治理中心:通过RAGFlow的向量数据库实现日志与文档的语义关联,自动标注“故障日志-解决方案”对应关系,形成可检索、可问答的 运维知识图谱,支持自然语言查询与 Root Cause 推荐。
核心 SQL 模板示例(实时业务损失计算)
INSERT INTO business_loss
SELECT switch_ip,interface,
error_count/10000 * unit_loss AS loss_cny,
CURRENT_TIMESTAMP AS calc_time
FROM network_events n
JOIN business_mapping b
ON n.switch_ip=b.switch_ip AND n.interface=b.interface
WHERE error_count>10000;4.2 数据全生命周期管理:
数据接入:引入行业专属数据源(如制造行业 PLC 数据、金融行业交易系统数据)通过 Flink CDC 同步数据库数据,Filebeat 采集日志数据,统一接入 Kafka 数据总线,通过数据格式校验(JSON Schema 验证)与行业数据标准适配;
数据清洗与标准化:通过 Spark SQL 去除重复数据、填充缺失值,建立行业统一的数据字典(如制造行业 “PLC 通信延迟” 指标定义、金融行业 “敏感操作日志” 字段规范)
数据质量监控:通过 Great Expectations 定义数据质量规则(如 “CPU 使用率范围 0-100%”),异常数据自动告警并触发重采,质量报告同步至 DataHub,供审计与模型训练参考。
4.3 数据安全与合规:
分级防护:按数据敏感度分级(高敏感:密码、交易数据;中敏感:设备配置;低敏感:公开监控数据),高敏感数据采用 “加密存储 + 访问双因子认证 + 操作审计”;
防泄露:敏感数据传输采用 TLS1.3 + 国密算法(SM4),访问时动态脱敏(如开发人员仅能查看脱敏后的 IP 地址),防止数据泄露;
合规适配:满足等保 2.0、SOX、GDPR 等合规要求,可自定义引入行业专属合规报表(如金融行业敏感操作审计报表、制造行业生产数据留存报表);
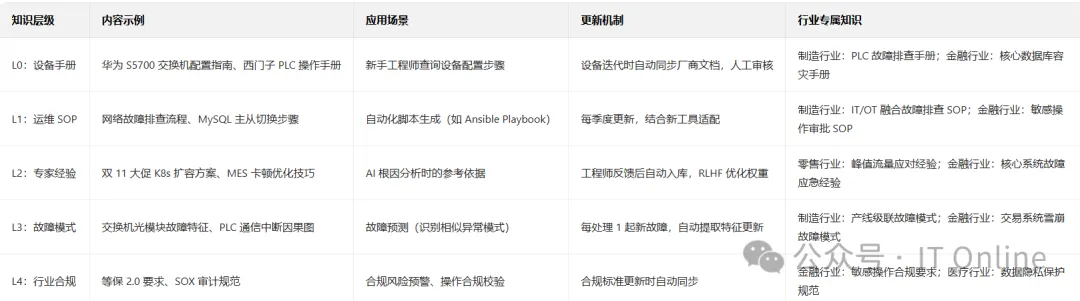
4.4 知识图谱构建:
基于 Neo4j 构建 “设备 - 系统 - 业务 - 合规” 四维知识图谱,如制造行业 “PLC - 产线 - MES - 生产工单” 关联、金融行业 “核心数据库 - 交易系统 - 客户 - 合规要求” 关联。当SCADA系统异常,AI可自动关联“是否因同一区域网络波动导致PLC通信中断”,通过RAGFlow 摄入:设备手册、配置指南,SOP流程(VMware快照清理规范)历史工单(2024年MES数据库慢因索引缺失)

五、智能层:AIGC驱动的决策大脑
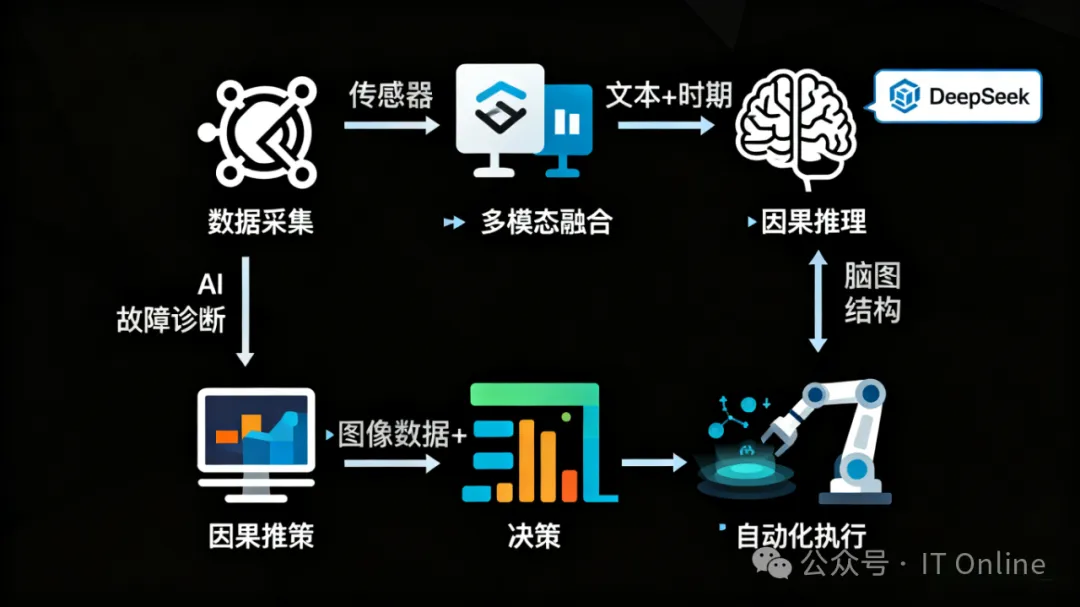
作为平台的“核心引擎”,以 “DeepSeek 行业大模型 + 多模态融合 + 因果推理” 为核心,实现 “从数据到行动” 的智能转化,解决 “人工决策滞后、准确率低、行业适配差” 的痛点。强化学习与AIGC技术,构建“诊断-预测-决策-生成”全链路智能能力,实现从“数据”到“行动”的跨越。
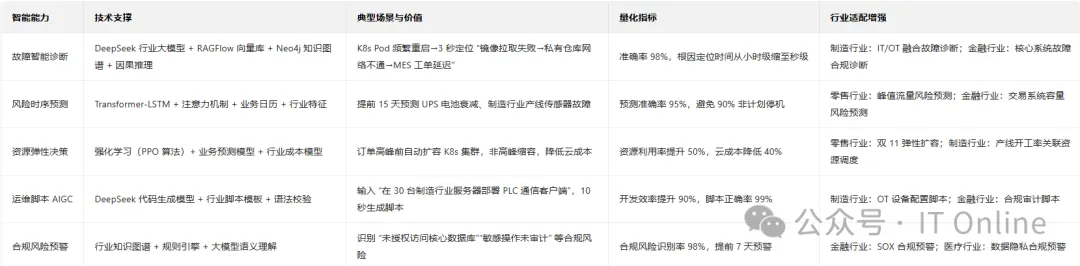
5.1 核心技术特性:
行业大模型微调:基于 DeepSeek-R2 开源模型,使用行业专属数据(如制造行业 IT/OT 故障案例、金融行业合规文档)进行微调,提升行业适配性,故障诊断准确率提升 10-15%;
多模态融合:融合文本(日志、工单)、时序(性能指标)、图像(设备指示灯、监控视频)、拓扑(资产依赖)多模态数据,如通过 “服务器指示灯红灯(图像)+CPU 100%(时序)+ 日志报错(文本)” 综合诊断硬件故障;
因果推理:突破传统 “相关性分析” 局限,通过因果图模型识别 “真正的故障根因”,如区分 “CPU 过载” 是 “业务高峰导致” 还是 “病毒攻击导致”,避免误判;
模型轻量化部署:针对边缘节点(如工厂边缘网关),部署轻量化模型(DeepSeek-Lite),实现本地故障诊断与自愈,降低云端依赖。
模型架构示例(DeepSeek-MoE 混合模型)
┌─ 主控模型:DeepSeek-V3-256K上下文(处理长周期故障分析)
├─ 专家模型1:DeepSeek-Coder-33B(Ansible playbook生成 & 配置审计)
├─ 专家模型2:DeepSeek-LLM-7B-Finance(ERP系统业务影响分析)
├─ 专家模型3:DeepSeek-Math-7B(时序预测 & 容量规划)
└─ 边缘模型:DeepSeek-Lite-1.3B(IoT边缘节点实时推理)MCP(Model Context Protocol)统一接入层:
# MCP协议定义:工具+资源+策略三位一体
@mcp.tool(
sandbox="isolated",
timeout=30,
require_approval="risk_level>3"
)
def ansible_execute(inventory: str, playbook_yaml: str, dry_run: bool = True):
"""AI执行Ansible前的安全校验"""
# OPA策略检查
policy_check = opa.evaluate("ansible_policy.rego", {
"playbook": playbook_yaml,
"inventory": inventory,
"user_context": mcp.current_user()
})
if not policy_check.allowed:
raise MCPSecurityException(policy_check.denied_reason)
# AI模拟执行(数字孪生验证)
simulation = digital_twin.simulate(playbook_yaml)
if simulation.impact_score > 0.1:
return {"require_human_approval": True, "risk": simulation.risk_report}
return ansible_runner.run(playbook_yaml, check_mode=dry_run)
@mcp.resource(stream=True)
def zabbix_topological_events():
"""实时拓扑感知事件流"""
return StreamingJsonl(
"zabbix://events?expand=topology&severity>=3",
enricher=ai_root_cause_enricher
)MCP(Model Context Protocol) 标准化上下文传递:
{
"context": {
"device": "H3C S6800-01",
"metric": "CPU > 95%",
"logs": ["...STP loop detected..."],
"business_impact": "影响生产线扫码入库"
},
"tools_available": ["ansible", "zabbix_ack", "hikvision_snapshot"]
}5.2 业务语义深度融合
通过 Dify 构建 “行业业务 - 技术映射知识库”,建立 “业务场景→技术指标→故障阈值→价值影响” 的四层映射,根据工程师角色(网络/系统/应用)动态调整召回策略,多模型协同诊断(Dify工作流)

场景映射:制造行业 “产线开工率 100%”→MES 系统 CPU 阈值从 80% 上调至 95%;金融行业 “交易日开盘前”→核心数据库内存阈值上调至 90%;
价值量化:制造行业 “PLC 通信中断 10 分钟”→“3 号产线 200 个工单延迟→直接经济损失 5 万元→生产良率下降 0.3%”;零售行业 “电商支付接口延迟 5 秒”→“下单转化率下降 2%→损失订单收入 10 万元”;
决策优先:基于业务价值优先级自动排序(如制造行业 “产线故障” 优先于 “办公网络故障”,金融行业 “交易系统故障” 优先于 “测试环境故障”)。
Dify 构建面向不同角色的AI助手~实现输入:多源告警 + 日志片段 + 资产拓扑 + 业务上下文,输出:根因分析 + 处置建议 + 影响范围报告。

Dify多智能体协同框架:
# Dify DSL定义:智能体工作流
workflow:
- agent: "diagnostic_agent"
model: "deepseek-coder"
tools: ["zabbix_api", "elk_query", "k8s_api"]
strategy: "贝叶斯网络+知识图谱RCA"
- agent: "impact_agent"
model: "deepseek-finance"
tools: ["erp_api", "mes_api", "crm_api"]
strategy: "业务语义影响评估"
- agent: "remediation_agent"
model: "deepseek-coder"
tools: ["ansible", "n8n", "k8s_operator"]
strategy: "生成式剧本+数字孪生预演"
- agent: "communication_agent"
model: "deepseek-llm"
channels: ["wechat_work", "dingtalk", "email"]
strategy: "角色化沟通(对CTO技术细节,对CEO业务影响)"业务-技术映射自动生成示例:
{
"business_event": "财务月结",
"technical": {
"db_mem_threshold": 90,
"approval_chain": ["财务经理", "IT总监"],
"compliance": ["SOX", "GB/T 22239"]
},
"financial_impact": {
"per_minute_loss": 50000,
"currency": "CNY"
}
}六、编排层:低代码驱动的自治执行平台
技术底座:n8n + MCP协议 + Ansible。MCP(Model Context Protocol)它为大模型提供了统一的工具调用接口,让DeepSeek能安全地操作基础设施。实现 “AI 决策→自动化执行” 的闭环,解决 “工具协同难、人工操作多、执行不安全、行业适配差” 的痛点。
6.1 核心技术底座
MCP 协议:标准化 AI 与工具的调用接口,“行业专属操作集”(如制造行业 PLC 参数配置、金融行业敏感操作审批)、“操作预校验 + 合规校验”(如执行敏感操作前校验合规权限)、“跨平台协同协议”(如 K8s 与 PLC 联动操作);
n8n 工作流引擎:集群部署 + 共享数据库,支持行业专属节点(如制造行业 PLC 操作节点、金融行业合规审批节点),可视化拖拽编排,支持 “条件分支 + 超时重试 + 回滚机制 + 子流程嵌套”,适配复杂行业场景;
Ansible 执行器:支持 Windows/Linux/ 工业系统跨平台适配,行业专属模块(如 PLC 配置模块、金融合规审计模块),支持离线部署与边缘执行,满足工业 / 金融等特殊环境需求;
零信任安全框架:融入零信任理念,所有操作执行前需经过 “身份认证 + 权限校验 + 合规校验 + 设备可信校验”,无信任默认,最小权限分配,关键操作全程加密与审计。
MCP Server定义示例:
{
"mcpServers": {
"network": {
"command": "python",
"args": ["/opt/mcp/network_server.py"],
"env": {
"ZABBIX_URL": "https://zabbix.corp.com",
"ANSIBLE_INVENTORY": "/etc/ansible/hosts"
},
"tools": [
{
"name": "get_switch_interface_status",
"description": "获取交换机端口状态",
"parameters": {
"switch_ip": {"type": "string"},
"interface_pattern": {"type": "string"}
}
},
{
"name": "shutdown_interface",
"description": "关闭指定交换机端口(需审批)",
"parameters": {
"switch_ip": {"type": "string"},
"interface": {"type": "string"},
"reason": {"type": "string"}
},
"approval_required": true // 高危操作需人工二次确认
}
]
}
}
}MCP Server 列表
mcp/network:latest # 网络设备
mcp/database:latest # 数据库
mcp/plc:latest # 工业 PLC
mcp/finance:latest # 金融合规
mcp/hospital:latest # 医疗生命体
mcp/retail:latest # 零售支付
...共 12 个自愈工作流编排(n8n):
// 工作流:ai-healing-orchestrator
[
{
"node": "MCP Client",
"action": "call_tool",
"tool": "network.get_switch_interface_status",
"arguments": { "switch_ip": "{{ $json.switch_ip }}", "interface_pattern": "Eth-Trunk1" },
"on_success": "analyze_with_llm",
"on_failure": "escalate_to_human"
},
{
"node": "DeepSeek Analysis",
"prompt": "接口CRC错误计数>10000,建议执行shutdown+replace cable。置信度: 0.92",
"routing": {
"confidence > 0.9": "auto_heal",
"0.7 < confidence < 0.9": "suggest_to_engineer",
"confidence < 0.7": "create_war_room"
}
},
{
"node": "Auto Healing",
"steps": [
"MCP: network.shutdown_interface",
"HTTP: 创建Jira工单(类型: 硬件故障)",
"Ansible: 发送邮件通知供应商( playbook: notify_vendor.yml )",
"WeChat: @网络工程师 'Eth-Trunk1已自动关闭,工单JIRA-1234已创建'"
],
"timeout": 300,
"rollback_on_error": true
}
]金融行业:核心数据库敏感操作审批工作流:
[
{
"node": "ELK日志触发",
"trigger": "核心数据库未授权访问尝试",
"output": {"db_ip": "10.0.0.10", "user": "test", "operation": "delete", "risk_level": "P0"}
},
{
"node": "合规校验节点",
"check": "用户无delete权限,操作违反SOX规范",
"output": {"approval_required": true, "approver": "IT安全主管"}
},
{
"node": "钉钉审批节点",
"action": "向IT安全主管推送审批通知",
"on_approve": "执行封禁操作",
"on_reject": "记录日志并告警"
},
{
"node": "Ansible执行",
"step": "下发iptables规则封禁违规IP,同步至堡垒机",
"audit": "操作哈希上链,防篡改"
}
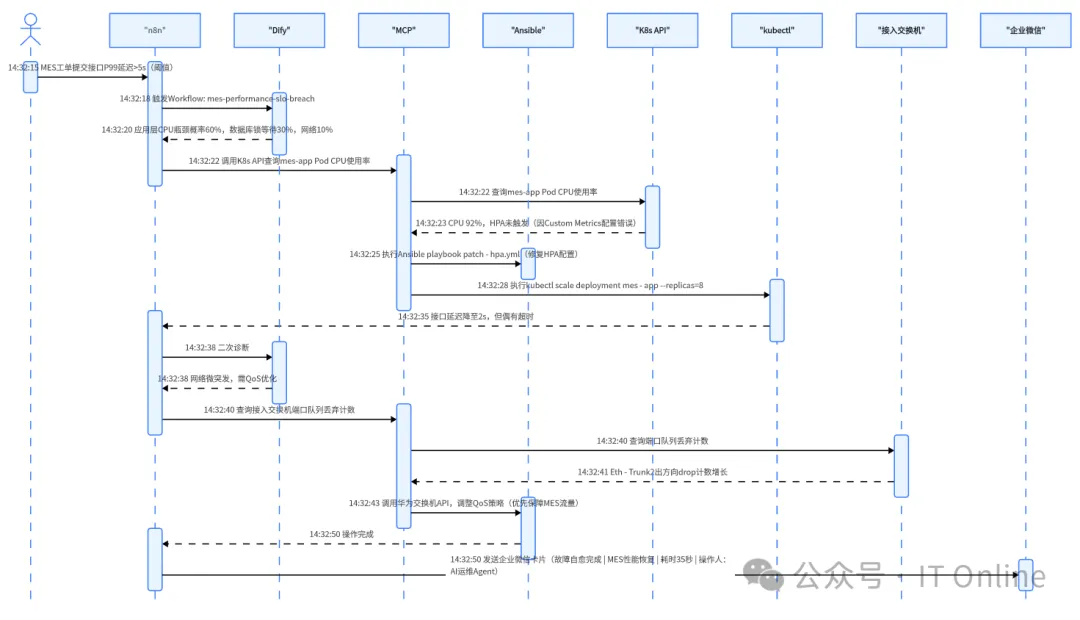
]6.2 典型场景:全栈故障自愈案例
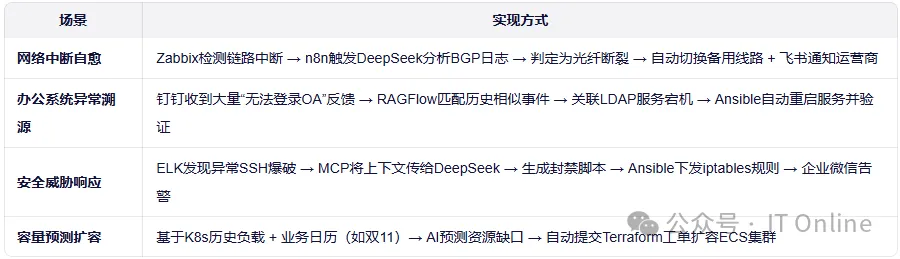
「MES系统卡顿 → 自动扩容 → 网络优化」级联故障恢复
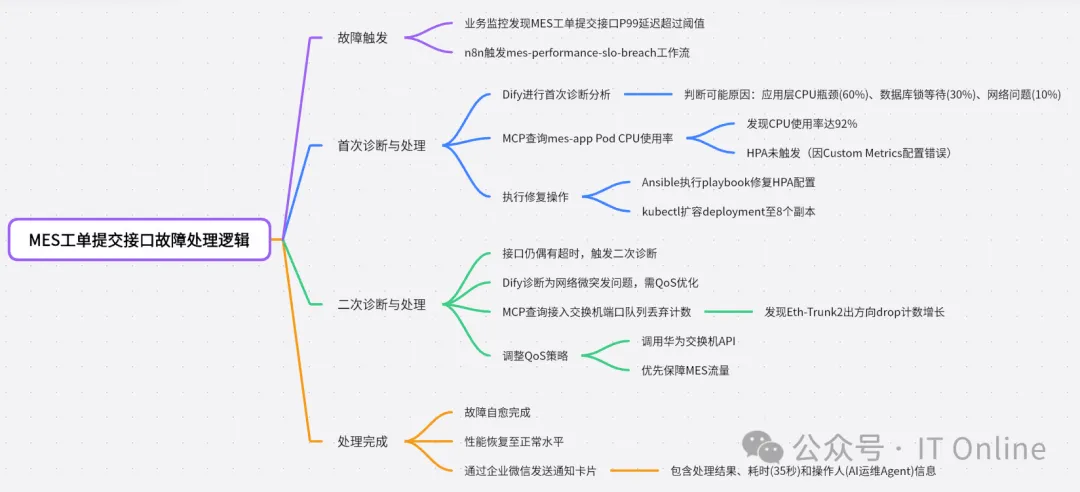
响应流程&人类工程师介入点:仅在「调整QoS策略」步骤,因涉及生产网络,AI生成配置后需网络工程师点击「批准」按钮(通过企业微信卡片交互)。
6.3 人机协同新范式:数字员工与虚实团队
组织架构演进
传统模式: 运维工程师 100% 手工操作
↓
自动化时代: 工程师 50% 脚本 + 50% 应急
↓
AI原生时代: 人机协同团队
├── 数字员工(AI Agent):处理80%标准化事务
├── 人类专家(SRE):专注架构优化、知识喂养、关键决策
└── 人机接口(n8n):定义协作边界、审批流、异常升级角色定义:
AI-Agent-Network:负责网络设备监控与自愈,技能树:CCIE知识体系
AI-Agent-Cloud:负责云资源调度,技能树:FinOps + K8s最佳实践
AI-Agent-Security:负责威胁检测与响应,技能树:ATT&CK框架
人类SRE:作为「教练」,持续给AI投喂优质案例,纠正AI误判
协作流程:
// 企业微信中@AI-Agent-Network
"帮我检查一下今晚割接方案的风险"
AI响应:
1. 解析割接方案PDF(RAGFlow检索)
2. 模拟故障注入(调用MCP: network.simulate_cut)
3. 生成风险清单:
- 风险1: 回滚窗口不足30分钟(历史类似失败率23%)
- 风险2: 缺少对MES系统的依赖检测
4. 建议:自动创建巡检工单,预置回滚Ansible脚本
5. 人类Review后,一键执行6.4 安全纵深设计
6.4.1 操作前防护:
影子模式:新工作流上线前,先 “记录不执行” 1 个月,人工 Review 无问题后再开放自动执行;
预校验机制:执行操作前,MCP 协议自动校验 “设备状态是否正常”“操作参数是否合法”(如关闭端口前检查是否有核心业务依赖);
6.4.2 操作中防护:
权限矩阵:按设备重要性分级(L1 核心 / L2 重要 / L3 普通),L1 设备(如核心交换机)操作需双因子确认(工程师 + 主管),L2 设备需单因子确认,L3 设备自动执行;
并发控制:同一设备同一时间仅允许执行 1 个关键操作(如避免同时扩容 + 重启 VM),防止操作冲突;
6.4.3 操作后防护:
操作审计区块链:关键操作(如关闭核心端口)的哈希值上链,防篡改,满足金融 / 国企合规要求;
结果验证:执行完成后,自动调用监控工具(如 Zabbix)验证操作效果(如切换线路后丢包率是否恢复正常),验证失败则触发回滚。
6.5 进化飞轮层 — 让系统「越用越聪明」
每处理 1 起运维事件,自动生成包含 “AI 诊断结果、人工修正方案、奖励信号” 的训练数据,实时更新知识图谱与模型参数:
# 反馈循环设计
每一次运维事件 → 生成数字孪生记录:
{
"incident_id": "INC-20241120-001",
"ai_diagnosis": {...},
"human_action": {
"engineer_id": "zhangsan",
"actual_root_cause": "网卡驱动bug",
"ai_accuracy": false,
"corrected_solution": "ethtool -G eth0 rx 4096 tx 4096"
},
"reward_signal": -1, # AI判断错误
# 自动触发
"knowledge_update": {
"ragflow": "插入修正后的案例",
"dify": "微调Prompt,增加驱动版本检查步骤",
"n8n": "更新工作流,在类似场景增加ethtool检查节点"
}
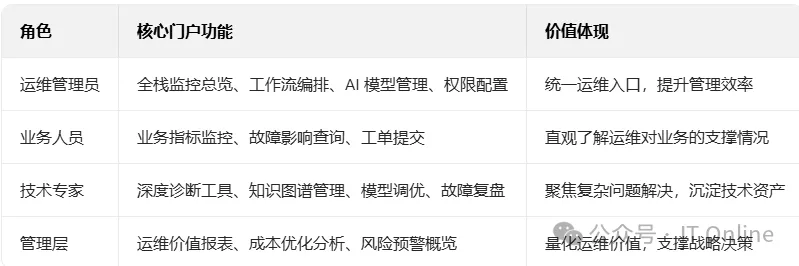
}七、应用层:面向全角色的价值化门户
为不同角色提供 “千人千面” 的运维入口,让运维价值直达业务场景,实现 “技术语言” 与 “业务语言” 的无缝转化。
7.1 核心功能模块:
7.2 多端协同支持:
桌面端:完整功能操作、可视化编排、深度分析工具;
移动端(企业微信 / 钉钉 / 飞书)故障告警推送、审批处理、快速查询、应急操作;
API 开放平台:支持与企业现有系统(OA、ERP、BI)无缝集成。
7.3 技术兼容性说明
平台要支持与企业现有运维工具无缝集成:
监控工具:Zabbix、Prometheus、Nagios 等;
数据工具:ELK Stack、ClickHouse、HDFS 等;
自动化工具:Ansible、Terraform、Jenkins 等;
协作工具:飞书、钉钉、企业微信、Jira 等;
云平台:阿里云、AWS、华为云、腾讯云等。
八、三纵支撑体系
8.1 安全体系:
数据安全:数据脱敏(IP / 密码替换为占位符)、传输加密(gRPC+TLS1.3)、存储加密(AES-256);
访问控制:OAuth2.0+RBAC 权限模型,支持细粒度权限控制(如 “仅允许查看某机房设备数据”);
合规审计:满足等保 2.0、SOX 等合规要求,自动生成审计报表(如 “敏感操作审计日志”“数据访问审计日志”);
8.2 标准体系:
数据标准:统一数据格式(如指标命名规范、时间戳格式)、数据字典(字段含义、类型、约束);
接口标准:MCP v1.0 协议规范、API 接口设计规范(RESTful 风格);
故障标准:故障分级标准(P0 - 紧急 / 1 小时内处理,P1 - 高优先级 / 4 小时内处理,P2 - 中优先级 / 8 小时内处理,P3 - 低优先级 / 24 小时内处理);
8.3 运营体系:
模型迭代:每周更新知识库,每月微调 AI 模型,每季度进行模型性能评估;
故障复盘:每月分析 10 个典型故障案例,优化工作流与 AI 决策逻辑;
用户反馈:建立工程师反馈渠道(如企业微信反馈群、反馈表单),收集使用问题与优化建议,24 小时内响应,1 周内落地可行建议;
培训体系:为运维人员提供工具使用(n8n/Dify)、AI 模型训练、故障诊断等培训,确保平台高效使用。
文章最后:
IT 行业没有那么多光鲜亮丽的聚光灯,更多的是 “悄悄努力、默默兜底” 的日常。故障突袭时,总有一群人第一时间扛起责任,为那句 “系统恢复了”,将家人的等候、朋友的邀约,轻轻搁在工作界面的后台 —— 这就是IT人的日常。他们心里装着整个企业系统的正常运转,业务的顺畅体验。IT不是边缘岗,IT人也不是只会敲代码的 “理工男”,他们是数字世界的 “守夜人”,是企业前行路上的 “铺路石”,用一次次坚守扛下责任,用一个个创新解决难题。那些藏在日志里的执着、代码里的热爱、故障解决后的释然,都是最实在的担当。这份不被常提却不可或缺的付出,值得被看见、被尊重 —— 因为他们撑起的,不仅是稳定的系统,更是这个时代滚滚向前的数字底气。愿每一位深耕技术的IT人,都能在坚守中收获成长,在创新中绽放光芒,继续用专业与热爱,与时俱进!


