
300 万 SYN 包致全网瘫痪?NTM 全流量回溯实战:10分钟锁定僵尸病毒,快速处置!
上午 8:40,公司运维监控群弹出告警:办公网出口带宽利用率骤升至 97%,多位同事反馈网页加载转圈、业务系统响应迟缓(虽早禁用抖音等娱乐平台,但基础办公网络已受影响)。从事政企网络运维 8 年,这类 “突发卡顿” 不算罕见,本打算按常规流程排查链路拥堵。没曾想 9:30,市场部、财务部接连紧急反馈:OA 系统登不上、ERP 无法提交单据、客户对接的业务平台直接超时,核心业务全面停摆,一场实打实的网络危机已然爆发。
排查过程复盘:

一、系统化排障:从现象到范围的精准收敛
1. 分层诊断:按 “终端 - 内网 - 边界 - 外网” 逐步验证
公司网络拓扑为 “办公终端 - 接入交换机 - 核心 IRF 双机 - 深信服防火墙 - 深信服 AC - 互联网”,结合 OSI 七层模型,按 “先易后难” 原则展开测试,统一用ping IP -t长 ping+-l 1024大包测试,确保结果更贴近实际业务场景:
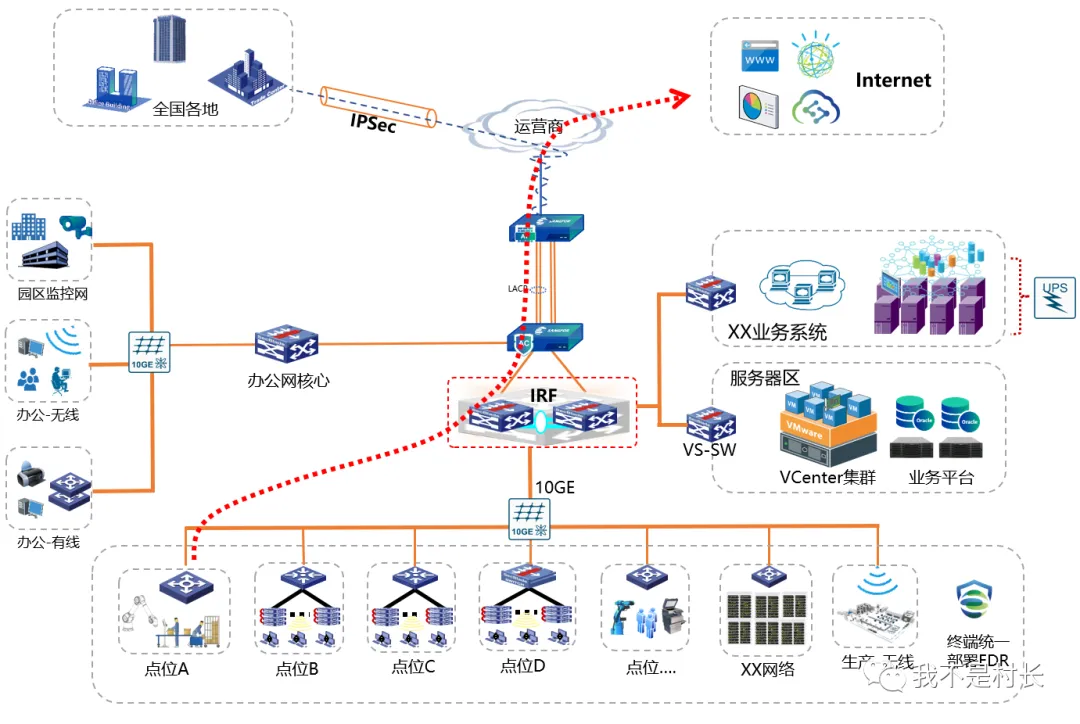
终端与接入层:同部门(同 VLAN)两台电脑互 ping,3000 包无丢包,延迟稳定在 2-4ms,抖动<3ms;登录接入交换机查看端口状态,无 CRC 错误、无端口 Down 告警,排除网线松动、网卡故障、接入交换机异常;
内网跨段:测试财务 VLAN(192.168.5.0/24)ping 技术部 VLAN(192.168.8.0/24),丢包率 63%,延迟忽高忽低(200-1500ms),部分时候直接 “请求超时”,初步判断核心交换到防火墙之间出了问题;
边界设备:ping 防火墙内网接口(10.0.0.1),1000 包丢包 81%,延迟峰值超 2000ms,还出现大量乱序报文;
外网连通:ping 114.114.114.114、8.8.8.8,均无稳定回应,丢包率 100%,外网彻底断联。
综合测试结果,故障范围精准锁定在 “防火墙及内网侧接入链路”。
2. 深度溯源:聚焦防火墙异常,排除硬件问题
远程登录核心 IRF 交换机(用 CRT 通过 SSH 登录,波特率 9600),做进一步验证:
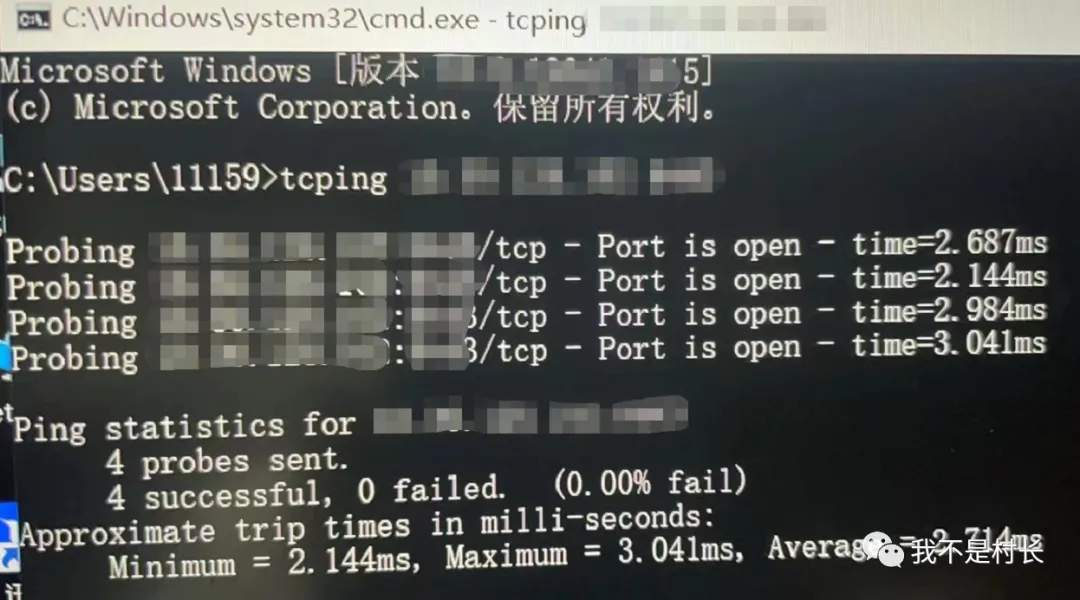
核心交换机端口检查:查看防火墙上联端口(GigabitEthernet1/0/20)流量统计(
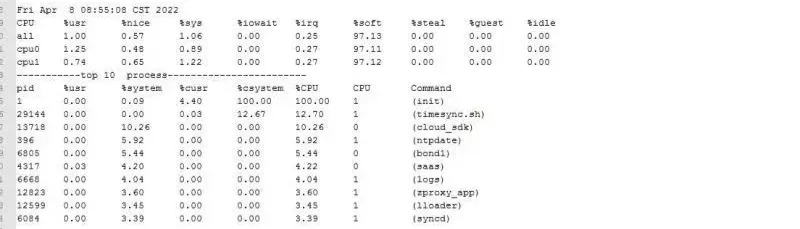
display interface GigabitEthernet1/0/20),入方向数据包速率达 11.2 万 pps,远超日常业务峰值(平时也就 8000-10000pps),但无帧丢失、无错误码,排除物理链路故障;跨设备连通性:核心交换机 ping 防火墙内网口,丢包率 75%,延迟抖动剧烈,但
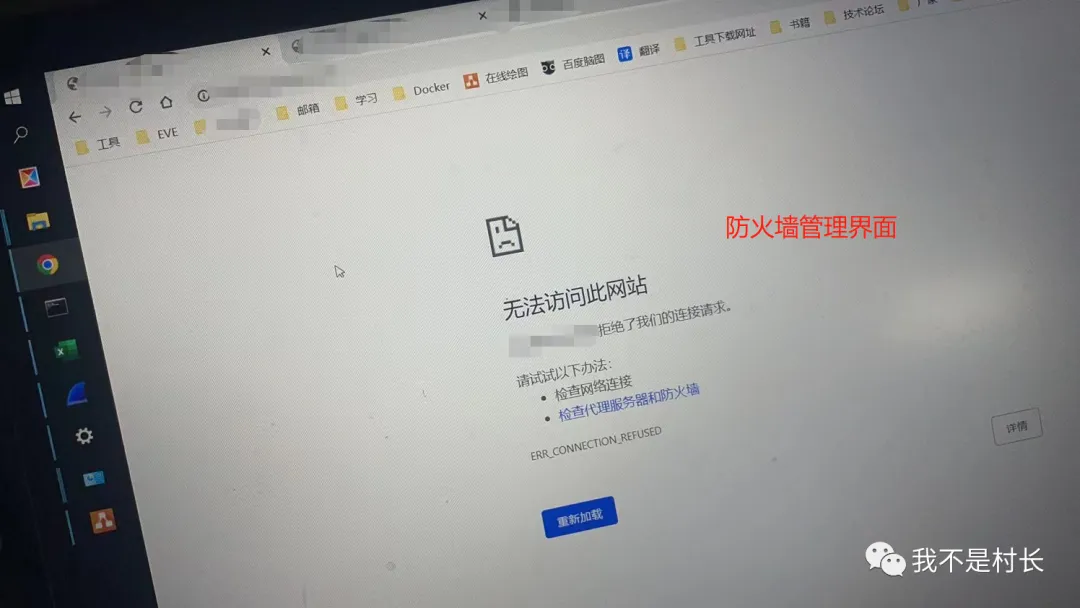
display arp | include 10.0.0.1显示 ARP 表项正常,排除地址解析问题;防火墙管理测试:尝试通过 Web 界面(HTTPS 443 端口)登录,报
ERR_CONNECTION_REFUSED;用 SSH 登录,超时失败;但tcping 10.0.0.1 443显示端口开放(响应时间 2.8ms),说明防火墙硬件没坏,大概率是系统进程阻塞或资源耗尽。
3. 常规修复:重启、冷启动均失效
按深信服防火墙运维手册,先尝试常规修复:
强制重启:通过 Console 口发送
reboot命令,重启后 5 分钟内,网络短暂恢复,随后又卡顿;冷启动:按标准流程下电,等 15 分钟再上电(彻底释放 CPU、内存资源),结果故障依旧;
配置回滚:用
display config对比,近期没做过配置变更,排除误操作导致的策略冲突;检查 License,也没过期或资源限制。
常规操作全没用,结合过往处理 DDoS 攻击的经验,果断启用公司刚部署 3 个月的 NTM 全流量回溯系统 —— 这是政企运维中排查复杂流量问题的 “硬家伙”,果然没让人失望。
二、硬核溯源:全流量分析锁定攻击 “真凶”
1. 流量画像:异常主机疯狂发 SYN 包
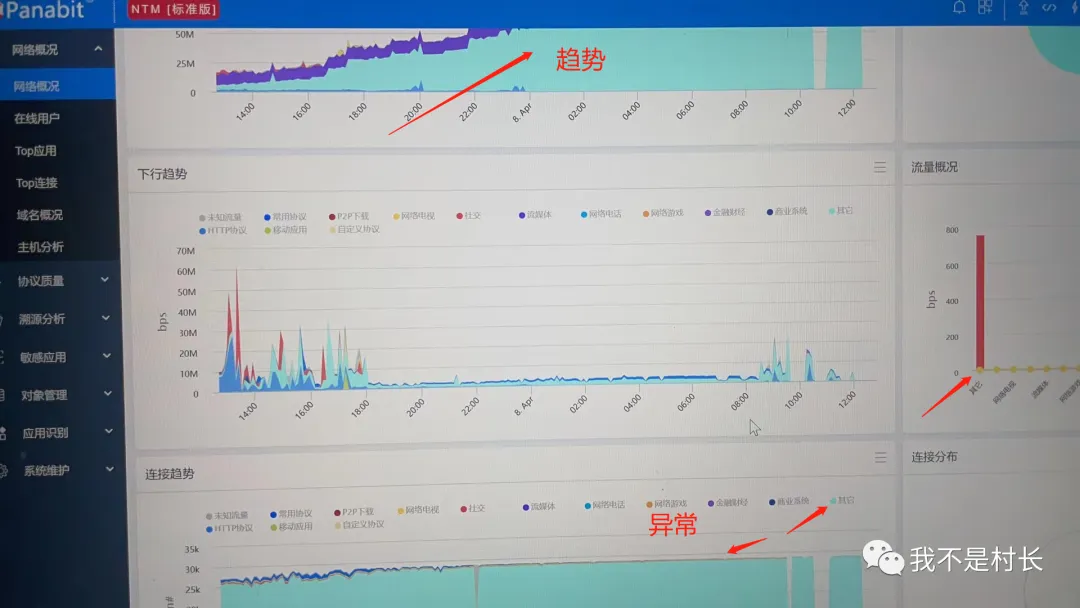
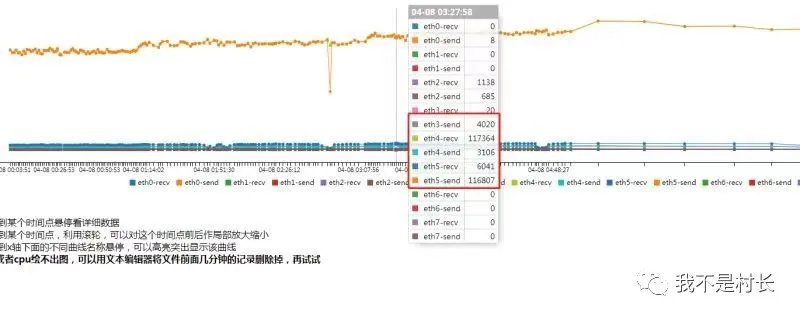
NTM 系统支持 10Gbps 线速采集、90 天全流量存储,打开后数据一目了然:
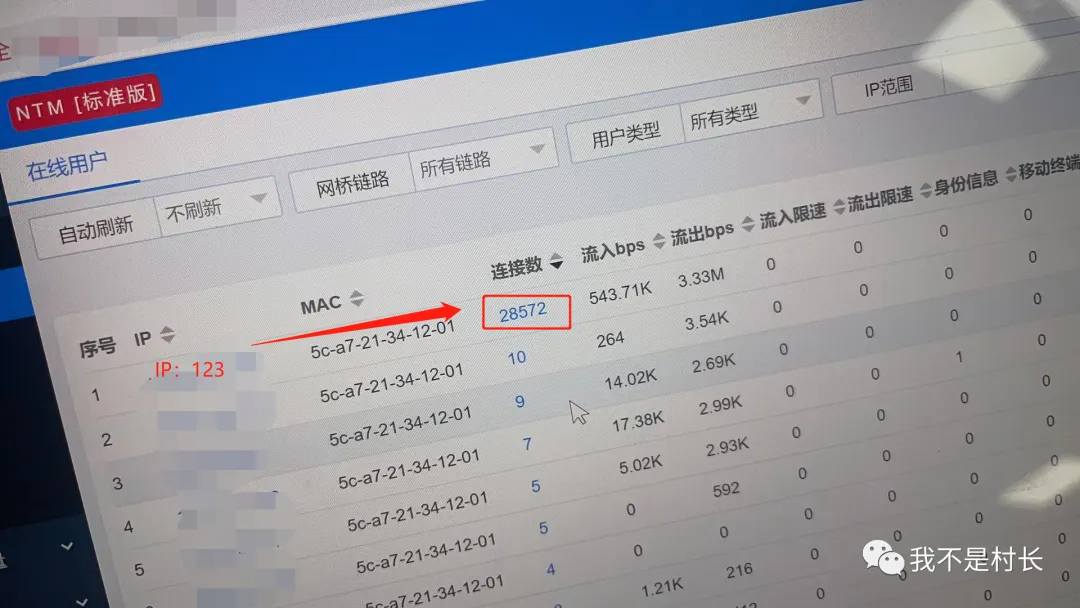
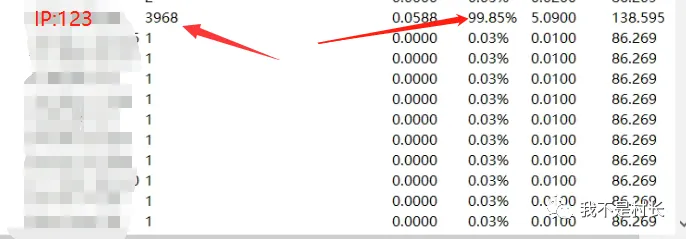
异常主机定位:“流量 TOP10” 里,IP:192.168.3.123(一台业务应用服务器)格外扎眼,出方向流量达 960Mbps,连接数峰值 28572,而正常业务连接数也就 300-500,流量和连接数都严重超标;
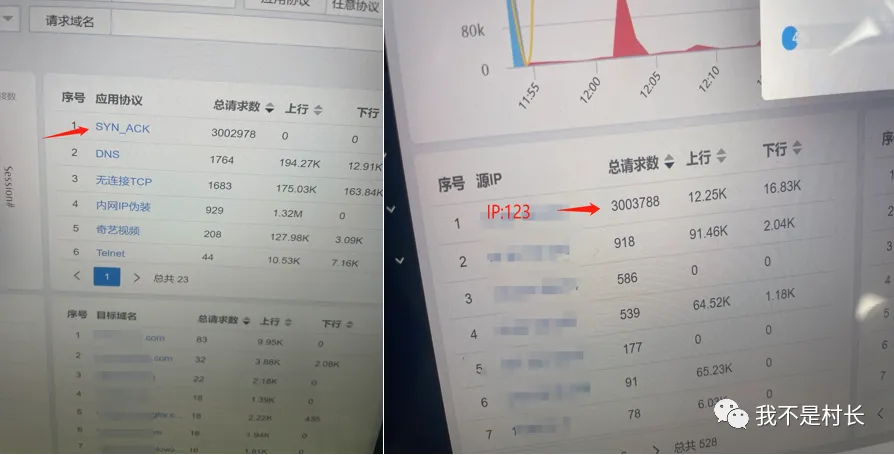
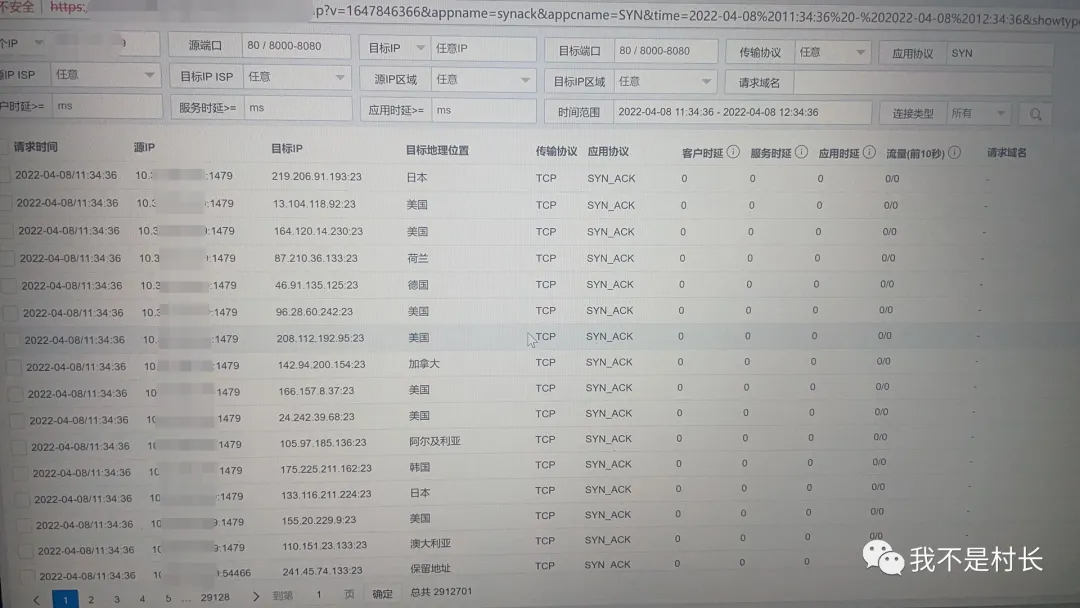
攻击行为解析:该主机 1 小时内对外发送 TCP SYN 报文 302 万次,平均每秒 840 多个,目标 IP 覆盖美国、日本、德国等 10 多个国家,且全是 23 端口(Telnet),源端口从 1024 到 65535 随机变化 —— 典型的 SYN_Flood 拒绝服务攻击特征;
协议诊断:TCP 协议异常占比 99.8%,SYN_ACK 响应率为 0(正常应>95%),防火墙的 TCP 半连接数已达最大阈值(16384),彻底被 “堵死”。
2. 多源验证:确认服务器感染僵尸病毒
防火墙日志佐证:用
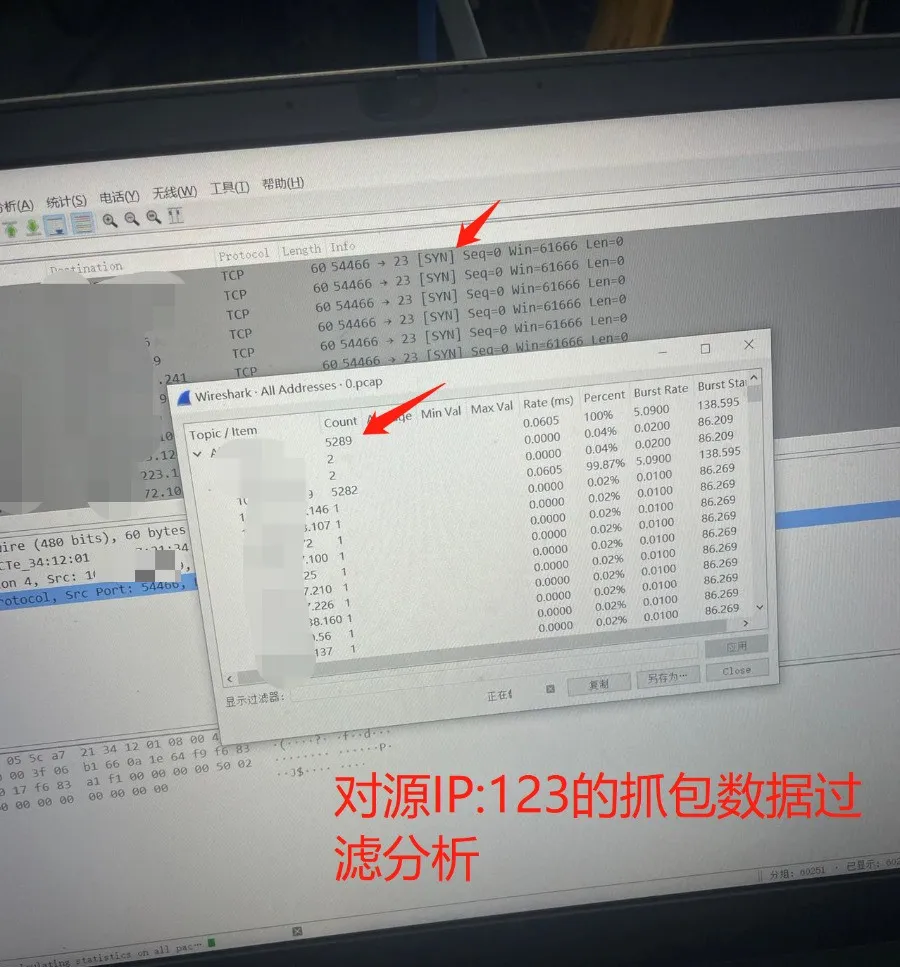
display logbuffer | include 192.168.3.123查看日志,内网口 eth4 接收数据包量暴增到 11.7 万 pps,CPU 负载高达 99.6%,还持续报 “会话表满溢”(Session Table Full),和 NTM 数据完全对得上;Wireshark 抓包:在核心交换机镜像端口用
tcpdump抓包(tcpdump -i GigabitEthernet1/0/20 host 192.168.3.123 -w attack.pcap),导出后用 Wireshark 分析,全是无状态的 SYN 报文,没有应用层数据,就是僵尸网络控制的 “肉鸡” 在发起攻击;
断网测试:拔掉防火墙内网口的网线,5 分钟后,防火墙 CPU 负载降到 4%,Web 管理界面能正常登录 —— 实锤了,故障就是这台服务器攻击导致的。
最终查明:IP:192.168.3.123 的业务服务器感染了 Mirai 变种僵尸病毒,被黑客控制后发起 SYN_Flood 攻击。核心交换机的包转发速率(240Mpps)远高于防火墙(10Mpps),海量攻击包让防火墙处理不过来,直接瘫痪,进而导致全网断联。
三、闭环处置:45 分钟恢复网络,深层加固防复发
1. 紧急隔离:快速切断攻击源
登录核心交换机,执行interface GigabitEthernet1/0/15; shutdown(该端口连接异常服务器),直接断开服务器的网络连接;同时在防火墙临时配置 ACL:acl number 3000; rule deny tcp source 192.168.3.123 0 destination-port eq 23,双重阻断攻击流量,避免扩散。
2. 边界加固:给防火墙 “减负”
启用 SYN Flood 防护:在防火墙配置
anti-ddos syn-flood cookie enable(SYN Cookie 机制),把 SYN 半连接超时时间设为 30 秒,单 IP 最大 SYN 连接数限制为 500;流量限速:针对内网所有主机,配置出方向 TCP 23 端口的流量限速(
qos car outbound acl 3001 cir 1024 kbps),防止再出现类似攻击;日志上报:把防火墙日志同步到 SIEM 平台,设置异常流量告警阈值,后续一旦出现高并发 SYN 包,立即弹窗提醒。
3. 服务器重构:根除安全隐患
病毒查杀:用卡巴斯基企业版全盘扫描,清除 Mirai 变种病毒及关联恶意进程(
botnet_mirai.exe),修复被篡改的tcpip.sys系统文件;系统重装:格式化系统盘,重新安装 Windows Server 2019,打上最新安全补丁(KB5030310、KB5030219);
安全加固:设置 16 位混合密码(大小写 + 数字 + 特殊符号),启用账户锁定策略(5 次错误登录锁定 30 分钟),彻底关闭 Telnet 服务(
sc config telnet start= disabled),用 firewalld 只开放业务必需的 8080、3306 端口;数据恢复:从异地备份服务器(公司配置 “每日增量 + 每周全量” 备份)恢复业务数据,用 MD5 校验确保数据完整,没有丢失。
整套操作下来,只用了 45 分钟,网络就恢复正常:核心业务系统访问延迟<10ms,丢包率 0%,外网出口带宽利用率回落至 18%,同事们能正常登 OA、用 ERP,客户对接的业务平台也恢复了响应。
四、运维复盘:政企网络安全要 “防患于未然”
这次故障是典型的 “服务器弱防护导致病毒感染,进而引发全网瘫痪”,给政企运维提了 3 个关键启示:
1. 排障要 “系统化 + 靠工具”
政企网络拓扑复杂,不能盲目重启设备,要按 “终端 - 内网 - 边界 - 外网” 分层排查,用数据说话;NTM 全流量回溯、Wireshark、tcping这些工具是 “救命稻草”,能快速定位异常,避免走弯路 —— 这也是政企运维必备的 “硬技能”。
2. 安全防护要 “全流程闭环”
事前防御:服务器不能图方便用弱密码(这次就是 admin/123456 被暴力破解),要启用强密码 + 账户锁定,关闭 Telnet、FTP 等冗余服务,按 “最小权限原则” 配置账户;
事中监测:部署 NTM、SIEM 等系统,实时监控流量异常,尤其是高并发 SYN 包、异常端口访问,早发现早处置;
事后处置:建立标准化 SOP,明确隔离、加固、恢复的步骤,同时异地备份必须到位 —— 政企业务数据不能丢,这是底线。
3. 运维要从 “救火” 变 “防火”
作为政企运维,不能只等着故障发生再处理,要主动优化:
升级防护设备:把防火墙从 10Mpps 升级到 100Mpps,提升 DDoS 攻击抵御能力;
部署终端安全:给所有服务器装 EDR,实时查杀病毒、自动修复漏洞;
加强培训:给业务部门管理员做安全培训,重点讲密码安全、服务器配置规范,避免因人为疏忽留漏洞。
政企网络安全无小事,一台服务器的弱防护,就可能导致全网业务停摆,损失不可估量。作为运维人员,既要懂技术、会用工具,更要建体系、防未然 —— 这才是政企运维 “技术大牛” 的核心价值,也是守护企业信息化生命线的关键。
原文链接:全流量回溯NTM-实战



