当AI大模型遇上网络巡检:从“人工熬夜”到“自动预警”的效率革命
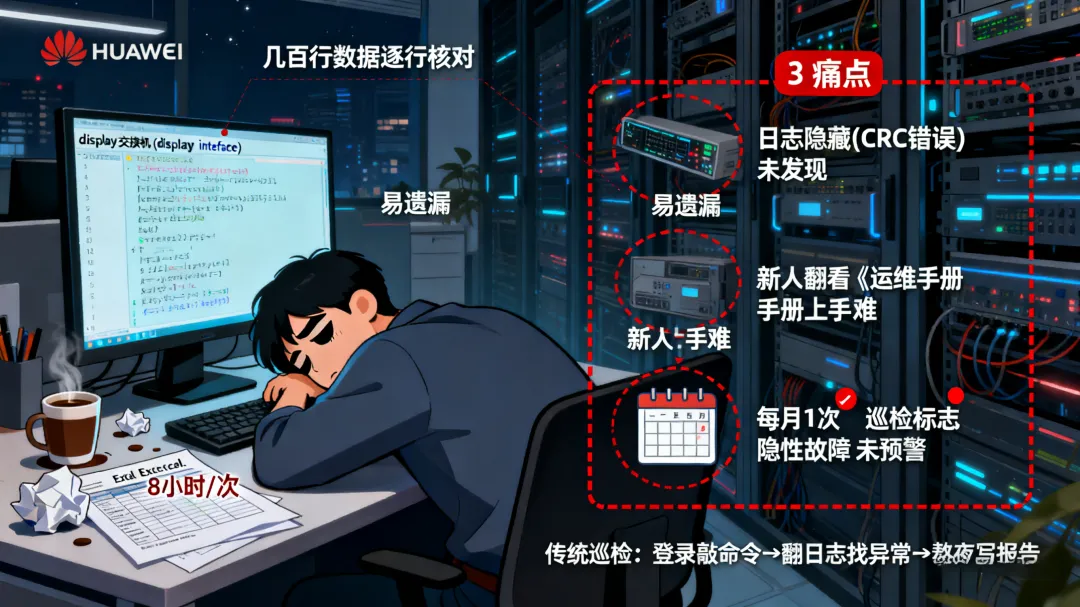
做网络运维的同学,大概都有过这样的经历:每月一次的全网设备巡检,要登录几十台路由器、交换机,逐条核对配置、检查端口状态、分析流量日志,熬到后半夜是常事;更头疼的是,例如华为交换机:人工巡检总绕不开 “登录设备敲命令、翻日志找异常、熬夜写报告” 的循环 —— 几十台设备要逐个排查,display interface输出的几百行数据得逐行核对,偶尔漏个 CRC 错误或配置漂移,就可能埋下网络中断的隐患。
但现在,随着 AI 大模型技术的成熟,这一切正在改变。我们可以尝试用 AI 大模型重构网络巡检流程,不仅把原本 8 小时的巡检工作压缩到 30 分钟,还可以实现 “异常提前预警”“问题自动定位”,运维效率直接翻了 10 倍。今天就跟大家聊聊,AI 大模型是如何落地网络自动化巡检的。
一、先说说传统网络巡检的 “痛点”:为什么我们一定要改变?
在引入 AI 之前,我们的网络巡检一直靠 “人工 + 脚本” 的模式,痛点特别突出:
效率低,耗时长:全网有 120 多台网络设备,每次巡检要登录每台设备的 CLI 界面,用命令行查看配置、端口、流量数据,再手动整理成 Excel 报告,一个人至少要 8 小时才能完成,遇到设备多的场景,还得拉上 2-3 人一起干。
易遗漏,容错率低:人工核对时,很容易忽略细节 —— 比如某台交换机的某个端口有偶尔的 CRC 错误,日志里只出现过 2 次,人工翻日志时大概率会漏掉,但时间久了可能导致端口断连。
依赖经验,新人上手难:巡检中的 “异常判断” 全靠老运维的经验,比如 “流量峰值超过多少算异常”“哪些配置变更有风险”,新人需要半年才能独立完成巡检,一旦老运维请假,巡检工作就容易断档。
事后补救,难提前预防:传统巡检是 “定期检查”,比如每月一次,要是设备在两次巡检之间出现隐性故障(比如路由协议偶尔抖动),只能等业务出问题了才会发现,属于 “事后补救”,无法提前预警。
二、AI 大模型如何落地网络自动化巡检?核心分 4 步
很多人觉得 “AI 大模型离网络运维很远”,其实落地起来并不复杂,我们的核心思路是 “让 AI 做‘翻译官’+‘分析师’+‘报告员’”,把运维人员从重复劳动中解放出来,专注于解决复杂问题。具体分 4 步:
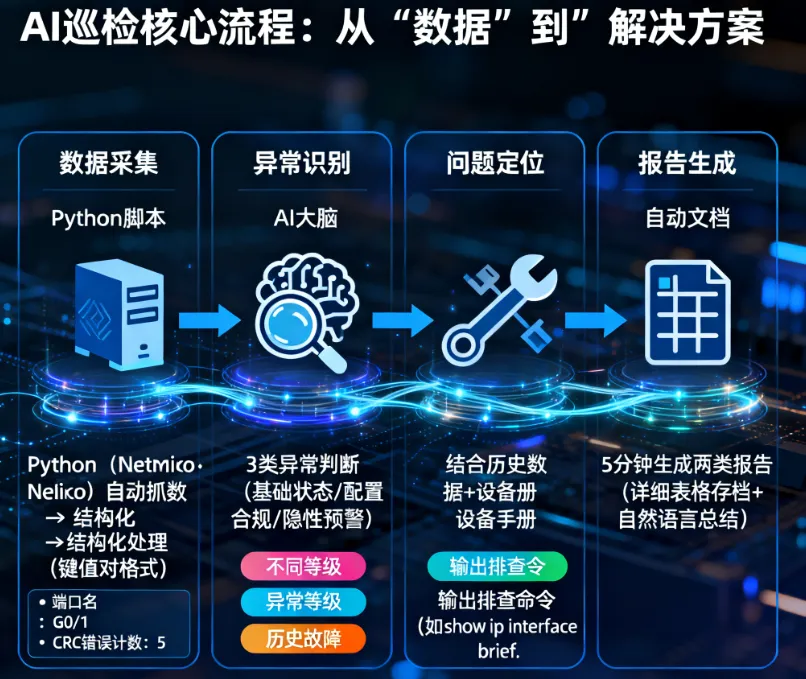
1. 第一步:数据采集 —— 让 AI “读得懂” 设备数据
网络设备的原始数据是 “命令行输出” 和 “日志文本”,比如用show interface命令得到的端口状态、用show log得到的系统日志,这些数据对人来说可读性低,对 AI 来说也需要 “预处理”。
我们做的第一件事,是搭建 “数据采集层”:
用 Python 脚本(结合 Netmiko、Paramiko 库)自动登录设备,批量执行巡检命令,把输出的文本数据抓取下来;
对数据进行 “结构化处理”:比如把端口状态中的 “up/down”“流量数值”“错误计数” 提取成键值对,把日志中的 “时间、事件类型、错误等级” 拆分成结构化字段;
把处理后的数据传给 AI 大模型(我们可以用的是本地化部署的 LLM,保证数据安全),同时给 AI 提供 “设备手册知识库”—— 比如某品牌交换机的端口错误阈值、路由协议的正常参数范围,让 AI 知道 “什么是正常,什么是异常”。
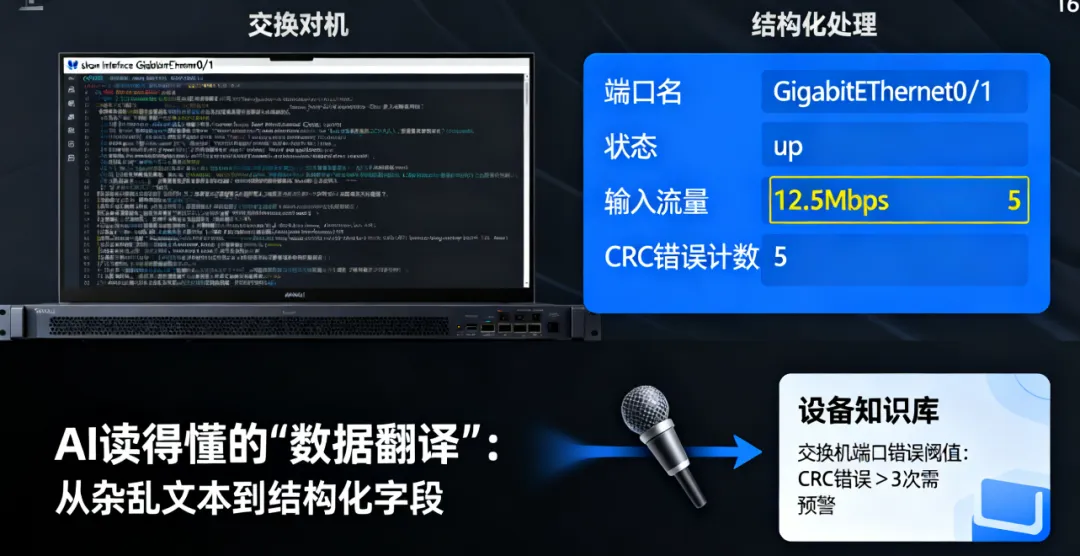
举个例子:原本show interface GigabitEthernet0/1的输出是一长串文本,经过处理后,会变成结构化数据:
{
"端口名": "GigabitEthernet0/1",
"状态": "up",
"输入流量": "12.5Mbps",
"输出流量": "8.3Mbps",
"CRC错误计数": 5,
"最近24小时错误增长": 3
}这样 AI 就能轻松 “读懂” 设备状态,不用再处理杂乱的文本。
2. 第二步:异常识别 —— 让 AI 当 “巡检员”,比人工更细致
数据采集完成后,AI 大模型的核心作用就是 “识别异常”,这一步相当于让 AI 代替人工做 “核对” 工作,而且比人工更细致、更严格。
我们给 AI 设定了 3 类 “异常识别任务”:
基础状态异常:比如端口状态为 “down” 但应该是 “up”、CPU 使用率持续超过 80%、内存占用超过阈值;
配置合规性异常:比如某台路由器的 OSPF 认证配置和标准模板不一致、交换机 VLAN 划分不符合规范;
隐性故障预警:比如端口 CRC 错误虽然没超过阈值,但 24 小时内增长了 3 次(可能是线路接触不良的前兆)、路由表有偶尔的波动(可能是协议不稳定)。
AI 识别异常的逻辑很简单:把实时采集的结构化数据,和 “知识库中的正常标准” 做对比,一旦发现不匹配,就标记为 “异常”。而且 AI 还能 “联想分析”—— 比如发现某台交换机的多个端口同时出现 CRC 错误,会自动关联 “是否是上联链路问题”,而不是单独判断每个端口。之前我们人工巡检时,曾漏掉过 “某交换机端口 CRC 错误增长” 的问题,后来 AI 在巡检中标记了这个异常,我们提前更换了网线,避免了后续的端口断连故障。
3. 第三步:问题定位 —— 让 AI 给运维 “当助手”,减少排查时间
传统巡检中,发现异常后,运维人员需要手动排查 “异常原因”,比如端口 down 了,要查是物理链路问题、配置问题还是设备硬件问题,可能需要 1-2 小时。而 AI 大模型能直接给出 “问题定位建议”,把排查时间压缩到 10 分钟以内。
我们的做法是,让 AI 结合 “历史故障库” 和 “设备知识库” 做分析:
比如 AI 发现 “端口 GigabitEthernet0/1 down”,会先查历史数据 —— 如果之前这个端口也出现过类似问题,且当时是因为网线松动,AI 会优先建议 “检查物理链路”;
如果是新问题,AI 会对照设备手册,列出可能的原因:“1. 物理链路中断;2. 端口配置错误;3. 设备硬件故障”,并给出对应的排查命令,比如 “执行 show ip interface brief 查看端口配置,执行 ping 命令测试链路连通性”。
例如 AI 发现某核心路由器的 OSPF 邻居关系偶尔中断,直接给出建议:“可能是 OSPF Hello 报文间隔不匹配,建议检查邻居设备的 hello-interval 配置”,我们按照建议去查,果然是两台设备的 Hello 间隔不一致,5 分钟就解决了问题,要是以前人工排查,至少要 1 小时。
4. 第四步:报告生成 —— 让 AI 自动写巡检报告,不用再熬夜整理
传统巡检的最后一步,是手动整理 Excel 报告,要把每台设备的状态、异常情况、处理建议一条条填进去,最费时间。现在,AI 大模型能自动生成 “结构化巡检报告”,甚至能生成 “自然语言总结”。
我们的报告分两部分:
详细报告:包含每台设备的基础信息、巡检项、异常列表、处理建议,用表格呈现,方便存档;
总结报告:用自然语言写清 “本次巡检覆盖多少设备、发现多少异常、高优先级异常有哪些、已处理多少、未处理的建议方案”,适合发给领导或团队同步。
比如 AI 生成的总结报告里会写:“本次巡检覆盖全网 120 台设备,发现异常 5 处,其中高优先级 2 处(1. 核心交换机 G0/1 端口 CRC 错误增长;2. 路由器 OSPF 邻居不稳定),已处理 3 处,剩余 2 处建议 24 小时内处理,具体方案见详细报告”。
现在,巡检完成后,AI 会在 5 分钟内自动生成报告,发到团队群里,运维人员不用再熬夜整理,省下来的时间可以做更有价值的工作,比如优化网络架构。
三、落地后的数据变化:效率翻 10 倍,故障减少 60%
某企业 AI 自动化巡检系统落地半年后,统计了一组数据,变化特别明显:
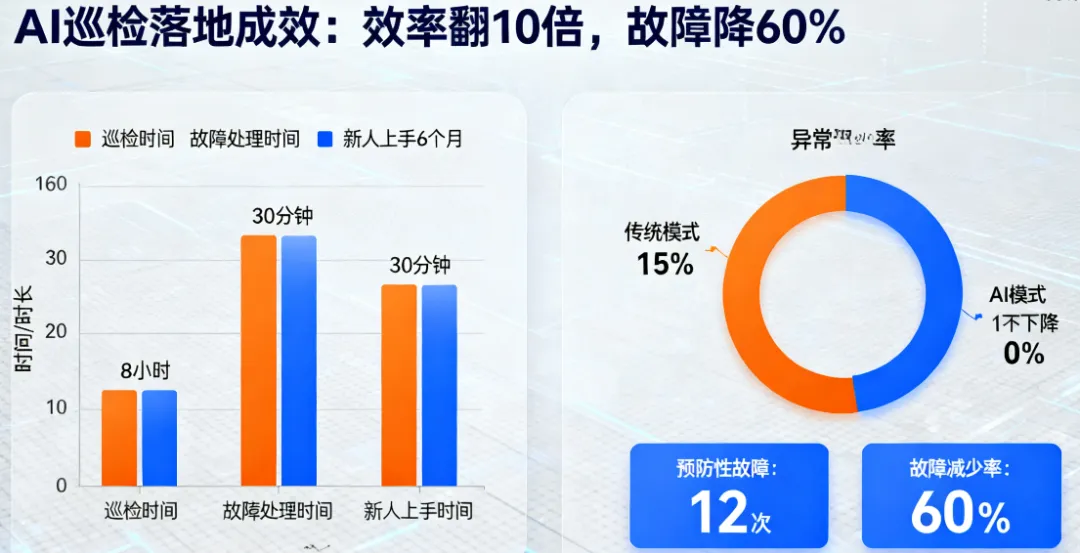
巡检时间:从原来的 8 小时 / 次,缩短到 30 分钟 / 次,效率提升 16 倍;
异常遗漏率:从原来的 15%(人工偶尔漏掉),降到 0%(AI 会检查每一个巡检项);
故障处理时间:从原来的平均 1 小时 / 个,缩短到平均 10 分钟 / 个;
预防性故障:通过 AI 预警,提前发现并解决了 12 次隐性故障,比去年同期的故障总数减少 60%;
新人上手时间:从原来的半年,缩短到 1 个月(新人跟着 AI 的建议学,很快就能独立处理问题)。
更重要的是,运维人员的工作状态变了 —— 以前每月要熬夜做巡检,现在只要看 AI 生成的报告,处理高优先级异常就行,不用再做重复劳动;而且因为故障减少,半夜被叫起来处理问题的次数也少了很多。
四、给想尝试的同学:3 个落地建议
很多人问我 “要不要跟风用 AI 做网络巡检”,其实不用盲目跟风,关键是结合自己的场景。这里给 3 个落地建议:
从 “小范围试点” 开始,不要一步到位:刚开始不用覆盖所有设备,可以先选 10-20 台核心设备做试点,跑通 “数据采集→AI 识别→报告生成” 的流程,验证效果后再扩大范围,避免一开始就遇到太多问题。
重视 “知识库建设”,AI 才能更精准:AI 的判断能力取决于 “知识库”,比如设备手册、标准配置模板、历史故障库,这些内容要提前整理好,而且要定期更新(比如新增设备型号时,补充对应的知识库),否则 AI 可能会判断失误。
AI 是 “助手” 不是 “替代者”,核心问题还是要靠人:AI 能处理重复的巡检工作、识别基础异常,但复杂问题(比如网络架构优化、新型故障排查)还是需要运维人员来解决。不要指望 AI 能 “包办一切”,而是让 AI 做 “重复性工作”,人做 “创造性工作”。
最后:AI 不是 “炫技”,而是让运维更轻松
很多人觉得 “用 AI 做网络巡检是炫技”,但对我们来说,AI 最大的价值是 “让运维人员不用再熬夜做重复劳动,有更多时间提升自己”。
以前,运维人员的时间都花在 “登录设备、查日志、写报告” 上;现在,这些工作交给 AI,运维人员可以专注于 “优化网络性能、设计灾备方案、学习新技术”。这才是 AI 给网络运维带来的真正改变 —— 不是替代人,而是让人做更有价值的事。
如果你也在被传统网络巡检的痛点困扰,不妨试试用 AI 大模型做些小尝试,也许会有不一样的收获。



